Kafka: A detailed overview
The basics
Apache Kafka is a framework for distributed streaming of data, while providing redundant storage of massive data volumes and a highly scalable message bus. Kafka is tailor-made for processing streaming data from real-time applications.
Apache Kafka’s architecture delivers an easy to understand approach to application messaging. Kafka is essentially a commit log with a very simplistic data structure. It happens to have an exceptionally fault-tolerant and horizontally scalable design.
The Kafka commit log provides a persistent ordered data structure. Records cannot be directly deleted or modified, only appended onto the log. The order of items in Kafka logs is guaranteed. The Kafka cluster creates and updates a partitioned commit log for each topic that exists. All messages sent to the same partition are stored in the order that they arrive. Because of this, the sequence of the records within this commit log structure is ordered and immutable. Kafka also assigns each record a unique sequential ID known as an offset, which is used to retrieve data by a consumer.
Kafka stores message data on-disk and in an ordered manner, hence it benefits from sequential disk reads. Considering the high resource cost of disk seeks, the fact that Kafka processes reads and writes at a consistent pace, along with the fact that reads and writes happen simultaneously without getting in each other’s way, combine to deliver very high performance.
Component Overview
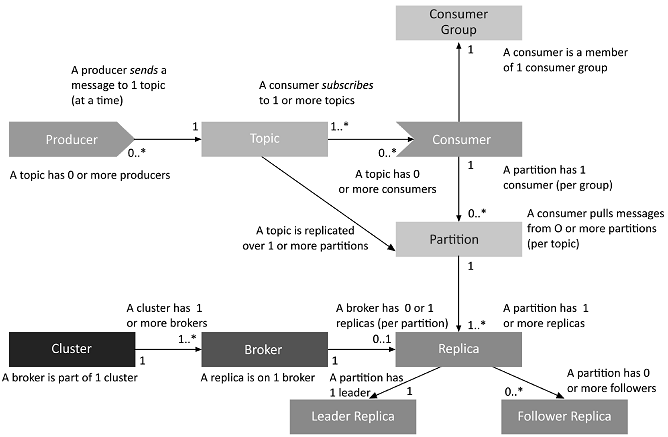
The Kafka architecture is made up of producers, consumers, consumer groups, clusters, brokers, topics, partitions, replicas, leaders, and followers. The relations between these components is as follows:
Kafka Topics
A Kafka topic is a channel through which records (data) are streamed. Producers publish messages to topics, and consumers read messages from the topic they subscribe to. Topics organize and structure messages, with particular types of messages published to particular topics. Topics are identified by unique names within a Kafka cluster, and there is no limit on the number of topics that can be created.
Kafka Partitions
Within the Kafka cluster, topics are divided into partitions (sharded), and the partitions are replicated across brokers (nodes in the Kafka cluster). From each partition, multiple consumers can read from a topic in parallel. It’s also possible to have producers add a key to a message. All messages with the same key will go to the same partition. While messages are added and stored within partitions in sequence, messages without keys are written to partitions in a round robin fashion. By leveraging keys, you can guarantee the order of processing for messages in Kafka that share the same key. This is a particularly useful feature for applications that require total control over records. There is no limit on the number of Kafka partitions that can be created (subject to the processing capacity of a cluster).
Kafka Architecture
Kafka Brokers
A Kafka cluster is made up of a several brokers (servers or nodes). This is to achieve load balancing and reliable redundancy and failover. Brokers utilise Apache ZooKeeper for the management and coordination of the cluster. Each broker has a unique ID and can be responsible for partitions of one or more topics. Kafka brokers also leverage ZooKeeper for leader elections, in which a broker is elected to lead the dealing with client requests for an individual partition of a topic. Connecting to any broker will bootstrap a client to the full Kafka cluster. To achieve reliable failover, topics must be replicated across brokers.
Apache ZooKeeper Architecture
Kafka brokers use ZooKeeper to manage and coordinate the Kafka cluster. ZooKeeper notifies all nodes when the topology of the Kafka cluster changes, including when brokers and topics are added or removed. For example, ZooKeeper informs the cluster if a new broker joins the cluster, or when a broker experiences a failure. ZooKeeper also enables leadership elections among brokers and topic partition pairs, helping determine which broker will be the leader for a particular partition (which will handle consumer reads and producer writes), and which brokers hold replicas of that same data. When ZooKeeper notifies the cluster of broker changes, they immediately begin to coordinate with each other and elect any new partition leaders that are required. This protects against the event that a broker is suddenly absent.
Kafka Producers
A Kafka producer serves as a data source that publishes messages to one or more Kafka topics. Kafka producers also serialise, compress, and load balance data among brokers through partitioning.
Kafka Consumers
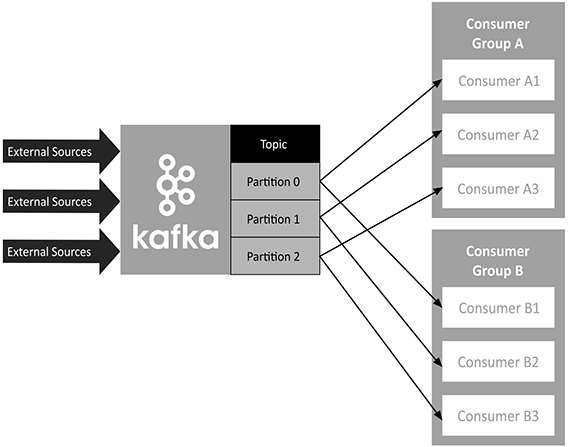
Consumers read data by reading messages from the topics to which they subscribe. Consumers will belong to a consumer group. Each consumer within a particular consumer group will have the responsibility for reading a subset of the partitions of each topic that it is subscribed to.
Consumer Groups
A Kafka consumer group includes related consumers that each do the same logical task. Kafka sends messages from partitions of a topic to consumers in the consumer group. At the time it is read, each partition is read by only a single consumer within the group. A consumer group has a unique group id, and can run multiple processes or instances at once. If the quantity of consumers within a group is greater than the number of partitions, some consumers will be inactive.
A Typical Kafka Cluster
Assembling the components detailed above, Kafka producers write to topics, while Kafka consumers read from topics. Topics represent commit log data structures stored on disk. Kafka adds records written by producers to the ends of those topic commit logs. Topic logs are sharded across one or more partitions, across multiple files and potentially multiple cluster nodes. Consumers can use offsets to start reading from certain locations within the topic logs. Consumer groups each remember the offset that represents the place they last read from a topic.
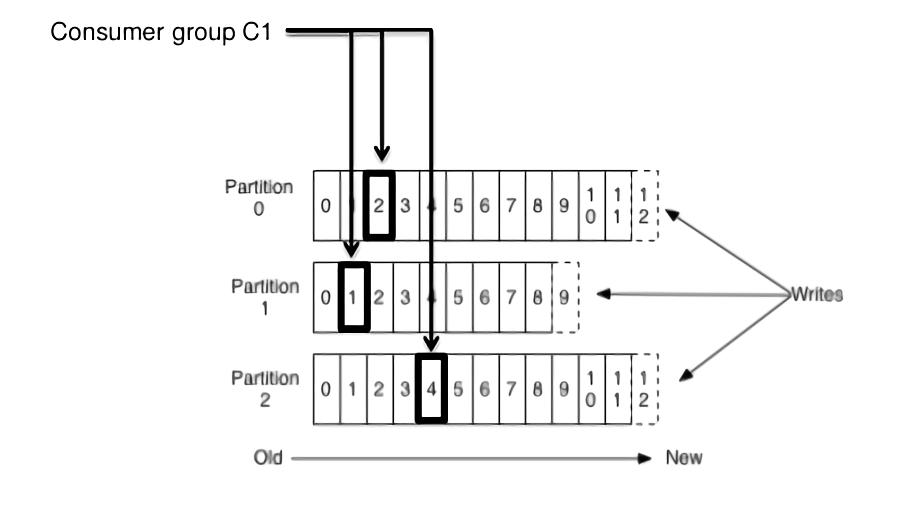
Horizontal application scalability and high performance can be achieved by simply by utilising additional consumers as needed in a consumer group to access topic log partitions replicated across nodes. This enables Apache Kafka to provide greater failover and reliability while at the same time increasing processing speed.
An important paramater is the Topic Replication Factor, which is essential to designing resilient and highly available Kafka deployments. When a broker goes down, topic replicas on other brokers will remain available to ensure that data remains available and that the Kafka deployment avoids failures and downtime. The replication factor that is set defines how many copies of a topic are maintained across the Kafka cluster. It is defined at the topic level, and takes place at the partition level.
For example, a replication factor of 3 will maintain three copies of a topic for every partition. As mentioned above, a certain broker serves as the elected leader for each partition, and other brokers keep a replica to be utilised if necessary. Logically, the replication factor cannot be greater than the total number of brokers available in the cluster. If a topic has 2 partitions, with a replication factor of 3, you would need 6 brokers. A replica that is up to date with the leader of a partition is said to be an In-Sync Replica (ISR).
Kafka architecture is built around emphasizing the performance and scalability of brokers. This leaves producers to handle the responsibility of controlling which partition receives which messages. A hashing function on the message key determines the default partition where a message will end up. If no key is defined, the message lands in partitions in a roundrobin fashion.
Kafka Component Relationships
- Kafka clusters may include one or more brokers.
- Kafka brokers are able to host multiple partitions (one replica of a partition from each topic, either leader replica if it is a leader for that topic partition, or a follower replica).
- Topics are sharded into one or more partitions.
- Each of a partition’s replicas has to be on a different broker.
- Each partition replica has to fit completely on a broker, and cannot be split onto more than one broker.
- Each broker can be the leader for zero or more topic/partition pairs.
Relationship between Producers, Consumers and Topics

While Producers can only send messages to one topic at a time, technically they can send messages to multiple topics in parallel by sending messages asynchronously.
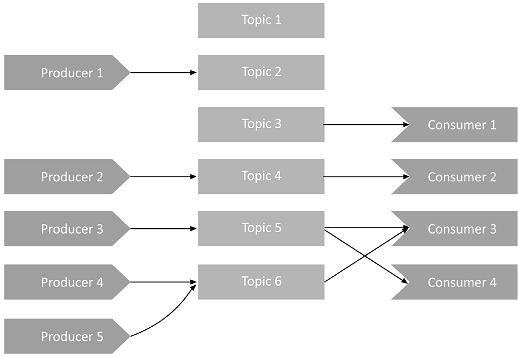
Consumers can subscribe to multiple topics at once and receive messages from them in a single poll (Consumer 3 in the image above shows an example of this). The messages that consumers receive can be checked and filtered by topic when needed (using the technique of adding keys to messages as explained before).
Scaling with Consumer Groups
A partition can connect to at most 1 consumer per group:
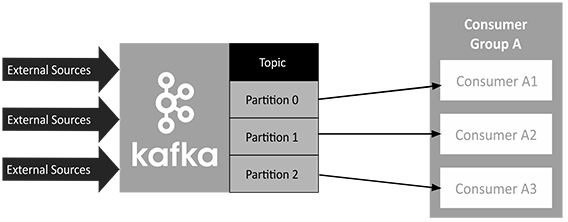
If there are fewer consumers in the consumer group compared to the number of partitions for the topic, one or more consumers would be bottlenecked by having to consume more than one partition.
If multiple consumer groups are subscribed to the same topic, the messages are broadcast to all groups:
Kafka’s dynamic protocol handles all the maintenance work required to ensure a consumer remains a member of its consumer group. When new consumer instances join a consumer group, they are also automatically and dynamically assigned partitions, taking them over from existing consumers in the consumer group as necessary. If and when a consumer instance dies, its partition will be reassigned to a remaining consumer in the same manner.